

As we discussed last week, the development of a realtime score, in which compositional materials can be continuously modified, re-arranged, or created ex nihilo during performance and displayed to musicians as musical notation, is no longer the stuff of fantasy. The musical and philosophical implications of such an advance are only beginning to be understood and exploited by composers. This week, I’d like to share some algorithmic techniques that I’ve been developing in an attempt to grapple with some of the compositional possibilities offered by realtime notation. These range from the more linear and performative to the more abstract and computation-intensive; they deal with musical parameters ranging from harmony and form to orchestration and dynamics. Given the relative novelty and almost unlimited nature of the subject matter (to say nothing of the finite space allotted for the task), consider this a report from one person’s laboratory, rather than anything like a comprehensive survey.
HARMONY & VOICE LEADING
I begin with harmony, as it is the area that first got me interested in modeling musical processes using computer algorithms. I have always been fascinated by the way in which a mechanistic process like connecting the tones of two harmonic structures, according to simple rules of motion, can produce such profound emotional effects in listeners. It is also an area that seems to still hold vast unexplored depths—if not in the discovery of new vertical structures[1], at the very least in their horizontal succession. The sheer combinatorial magnitude of harmonic possibilities is staggering: consider each pitch class set from one to twelve notes in its prime form, multiplied by the number of possible inversional permutations of each one (including all possible internal octave displacements), multiplied by the possible chromatic transpositions for each permutation—for just a single vertical structure! When one begins to consider the horizontal dimension, arranging two or more harmonic structures in succession, the numbers involved are almost inconceivable.
The computer is uniquely suited to dealing with the calculation of just such large data sets. To take a more realistic and compositionally useful example: what if we wanted to calculate all the inversional permutations of the tetrachord {C, C#, D, E} and transpose them to each of the twelve chromatic pitch levels? This would give us all the unique pitch class orderings, and thus the complete harmonic vocabulary, entailed by the pitch class set {0124}, in octave-condensed form. These materials might be collected into a harmonic database, one which can we can sort and search in musically relevant ways, then draw on in performance to create a wide variety of patterns and textures.
First we’ll need to find all of the unique orderings of the tetrachord {C, C#, D, E}. A basic law of combinatorics states that there will be n! distinct permutations of a set of n items. This (to brush up on our math) means that for a set of 4 items, we can arrange them in 4! (4 x 3 x 2 x 1 = 24) ways. Let’s first construct an algorithm that will return the 24 unique orderings of our four-element set and collect them into a database.
example 1
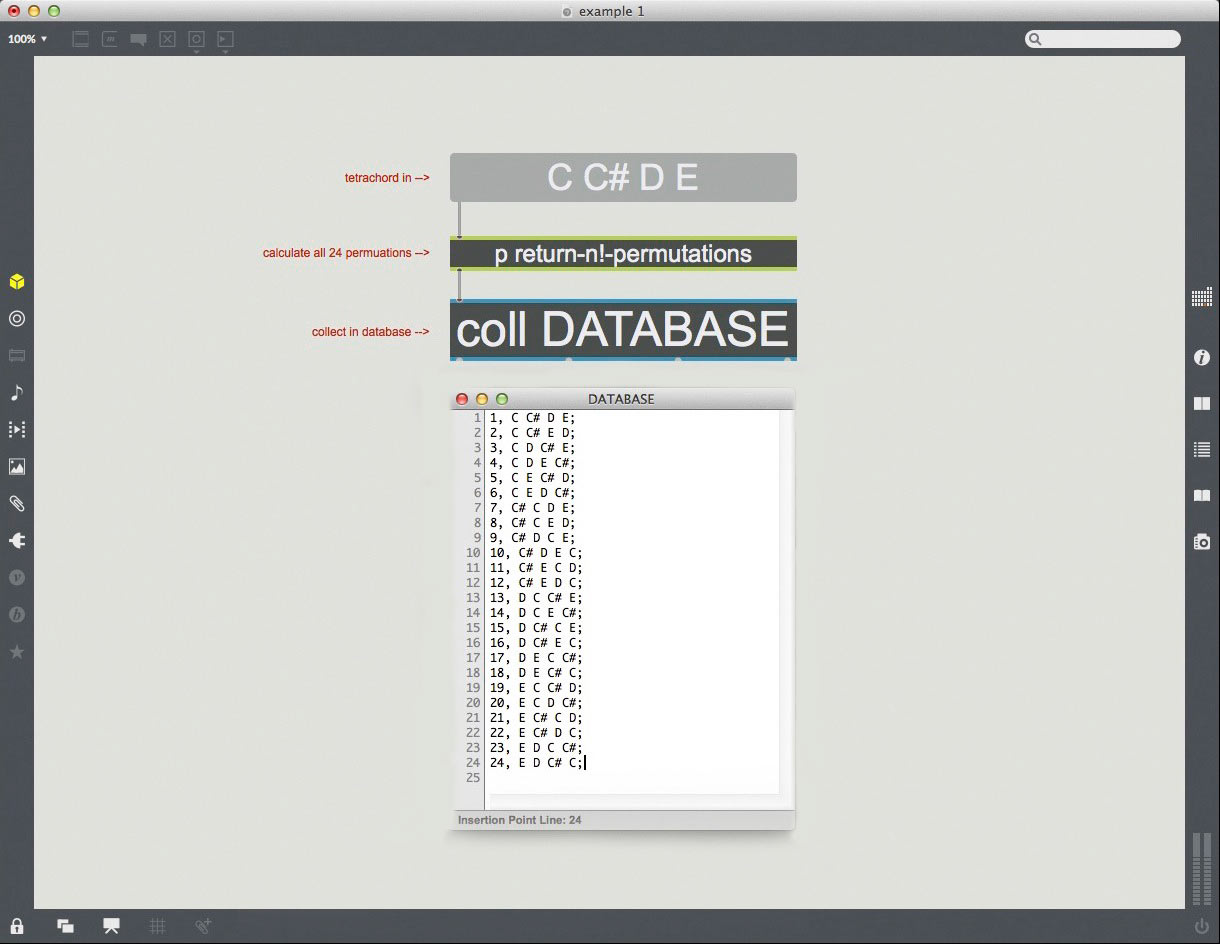
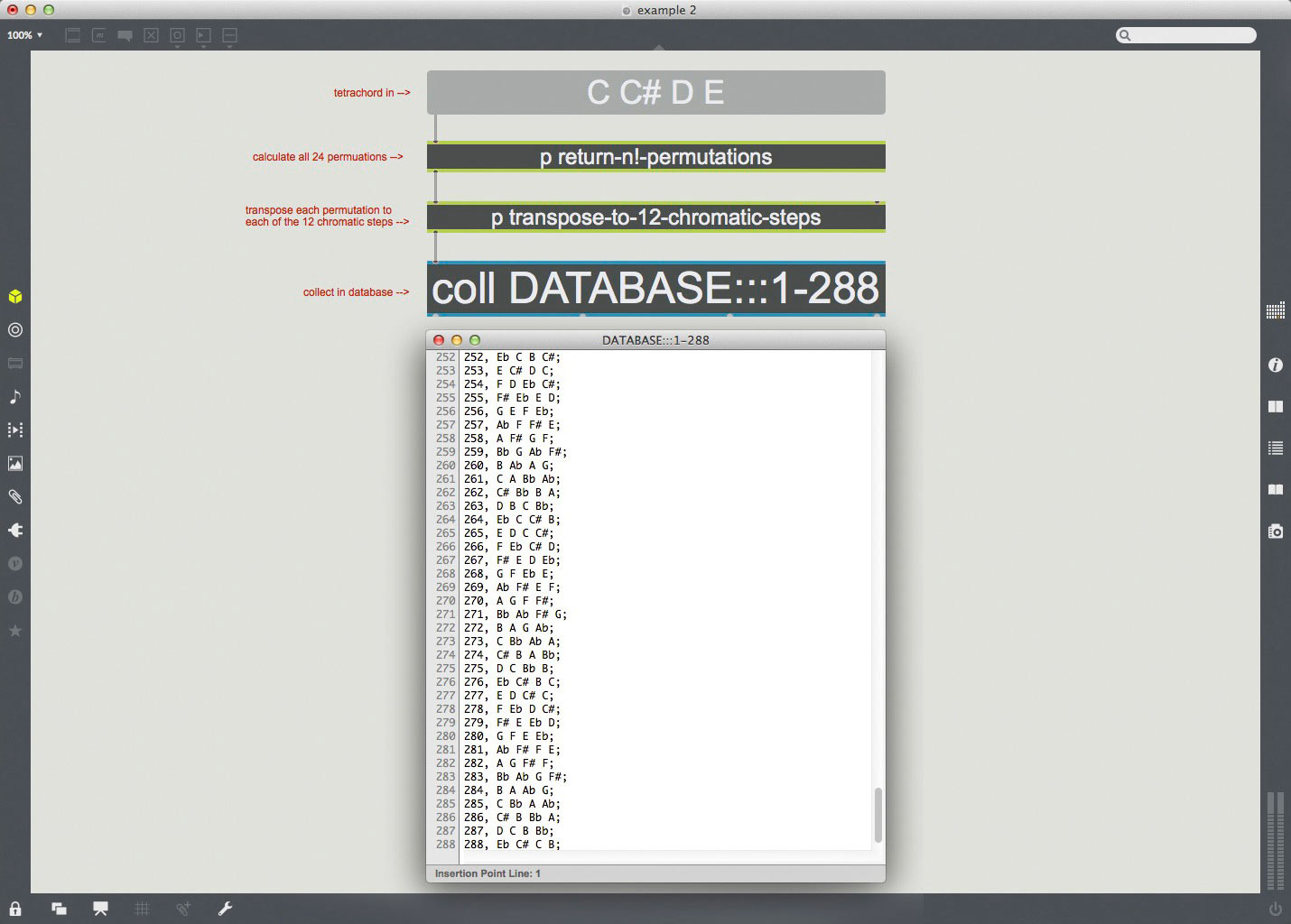
Next, we need to transpose each of these 24 permutations to each of the 12 chromatic steps, giving us a total of 288 possible structures. To work something like this out by hand might take us fifteen or twenty minutes, while the computer can calculate such a set near-instantly.
example 2
The question of what to do with this database of harmonic structures remains: how might we begin to create something musically satisfying from just this raw vocabulary? The first thing to do might be to select a structure (1-288) at random and begin to connect it with other structures by a single common tone. For instance, if the first structure we draw is number 126 {F# A F G}, we might create a database search tool that allows us to locate a second structure with a common tone G in the soprano voice.
example 3:
To add some composer interactivity, let’s add a control that allows us to specify which voice to connect on the subsequent chord using the numbers 1-4 on the computer keypad. If we want to connect the bass voice, we can press 1; the tenor voice, 2; the alto voice, 3; or the soprano voice, 4. Lastly, let’s orchestrate the four voices to string quartet, with each structure lasting a half note.
example 4:
This is a very basic example of a performance tool that can generate a series of harmonically self-similar structures, connect them to one another according to live composer input, and orchestrate them to a chamber group in realtime. While our first prototype produces a certain degree of musical coherence by holding one of the four voices constant between structures, it fails to specify any rules governing the movement of the other three voices. Let’s design another algorithm whose goal is to control the horizontal plane more explicitly and keep the overall melodic movement a bit smoother.
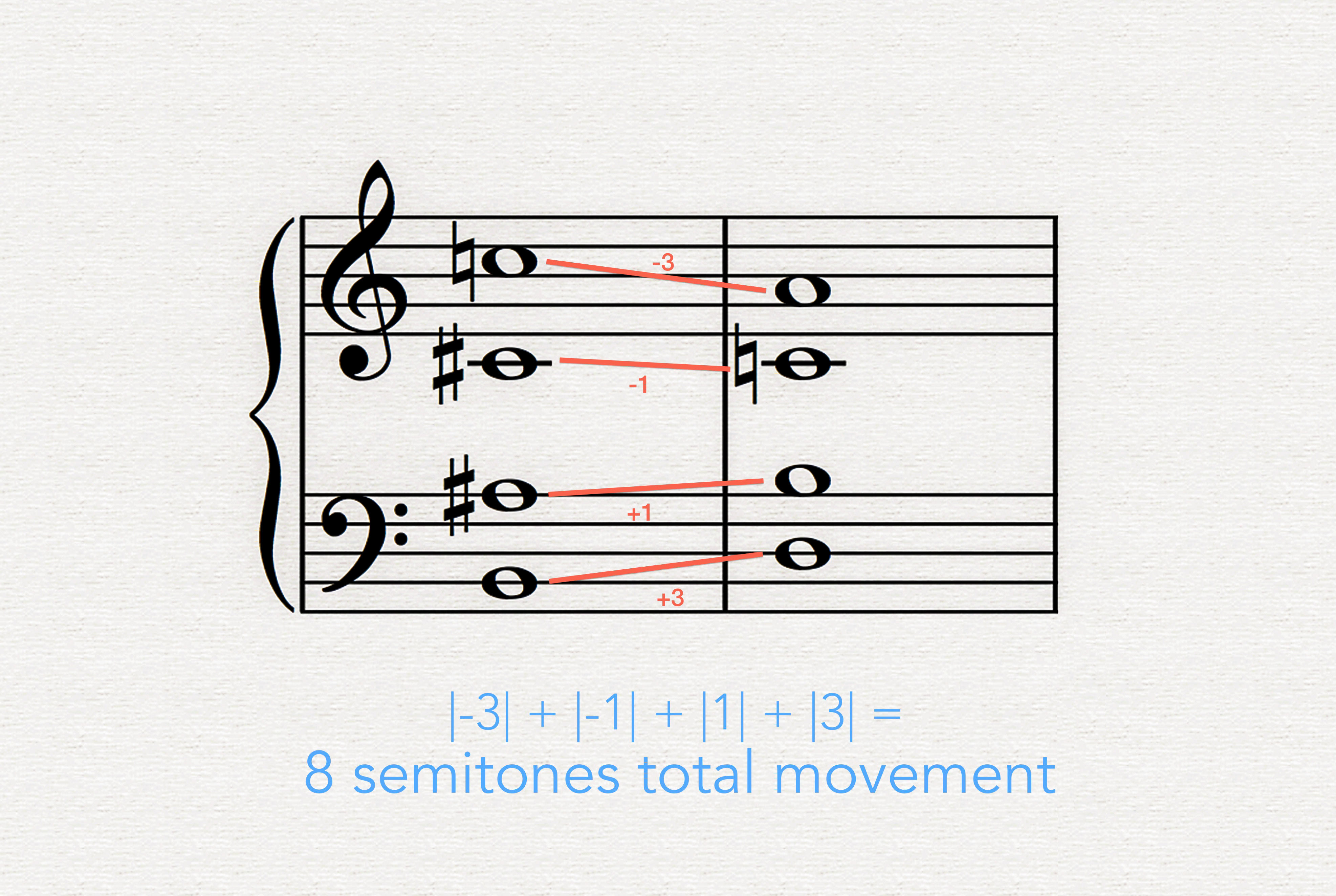
A first approach might be to calculate the total melodic movement between the current structure and each candidate structure in the database, filtering out candidates whose total movement exceeds a certain threshold. We can calculate the total melodic movement for each candidate by measuring the distance in semitones between each voice in the current structure and the corresponding voice in the candidate structure, then adding together all the individual distances.[2]
example 5.0
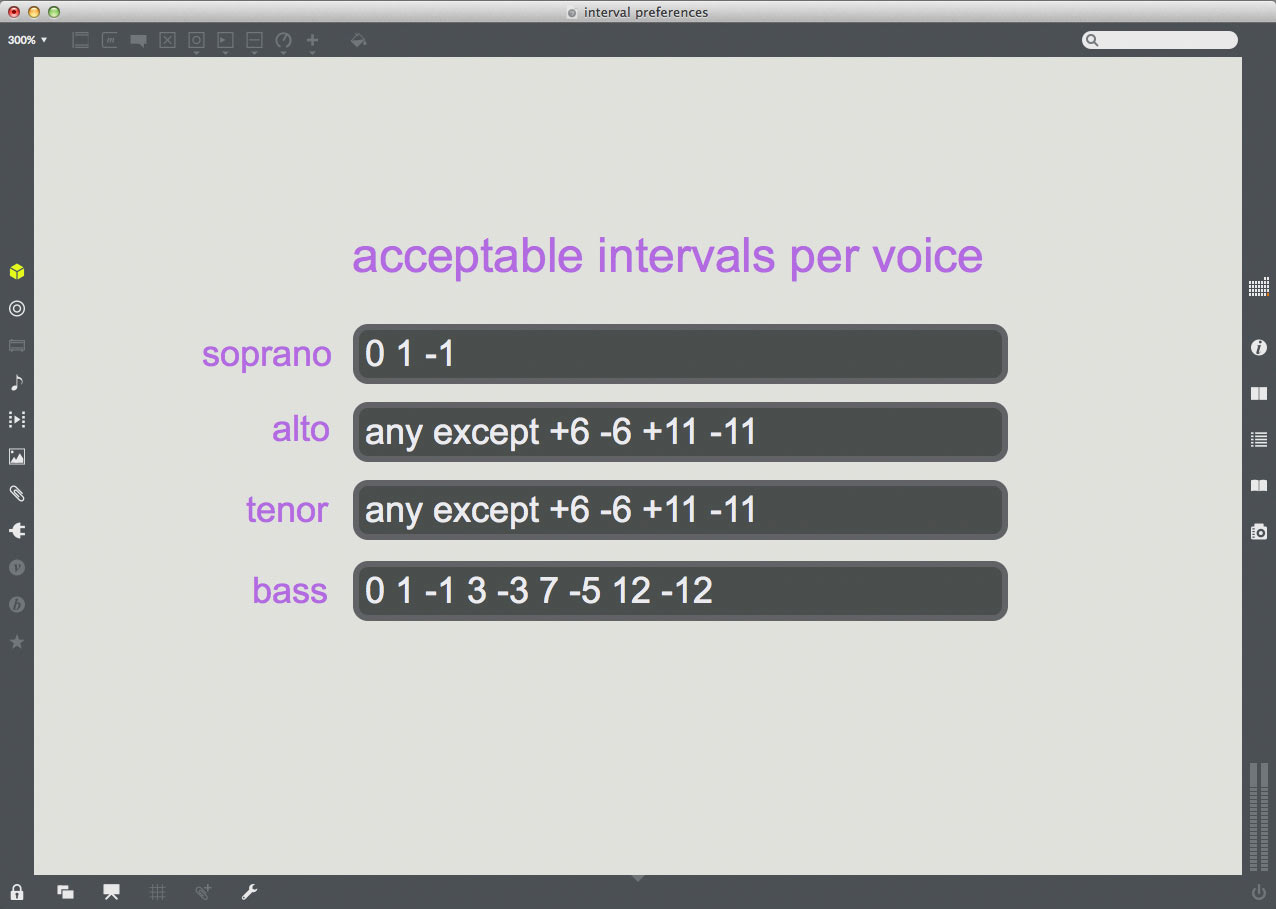
While this technique will certainly reduce the overall disjunction between structures, it still fails to provide rules that govern the movement of individual voices. For this we will need an interval filter, an algorithm that determines the melodic intervals created by moving from the current structure to each candidate and only allows through candidates that adhere to pre-defined intervallic preferences. We might want to prevent awkward melodic intervals such as tritones and major sevenths. Or perhaps we’d like the soprano voice to move by step (ascending or descending minor and major seconds) while allowing the other voices to move freely. We will need to design a flexible algorithm that allows us to specify acceptable/unacceptable melodic intervals for each voice, including ascending movement, descending movement, and melodic unisons.
example 5.1
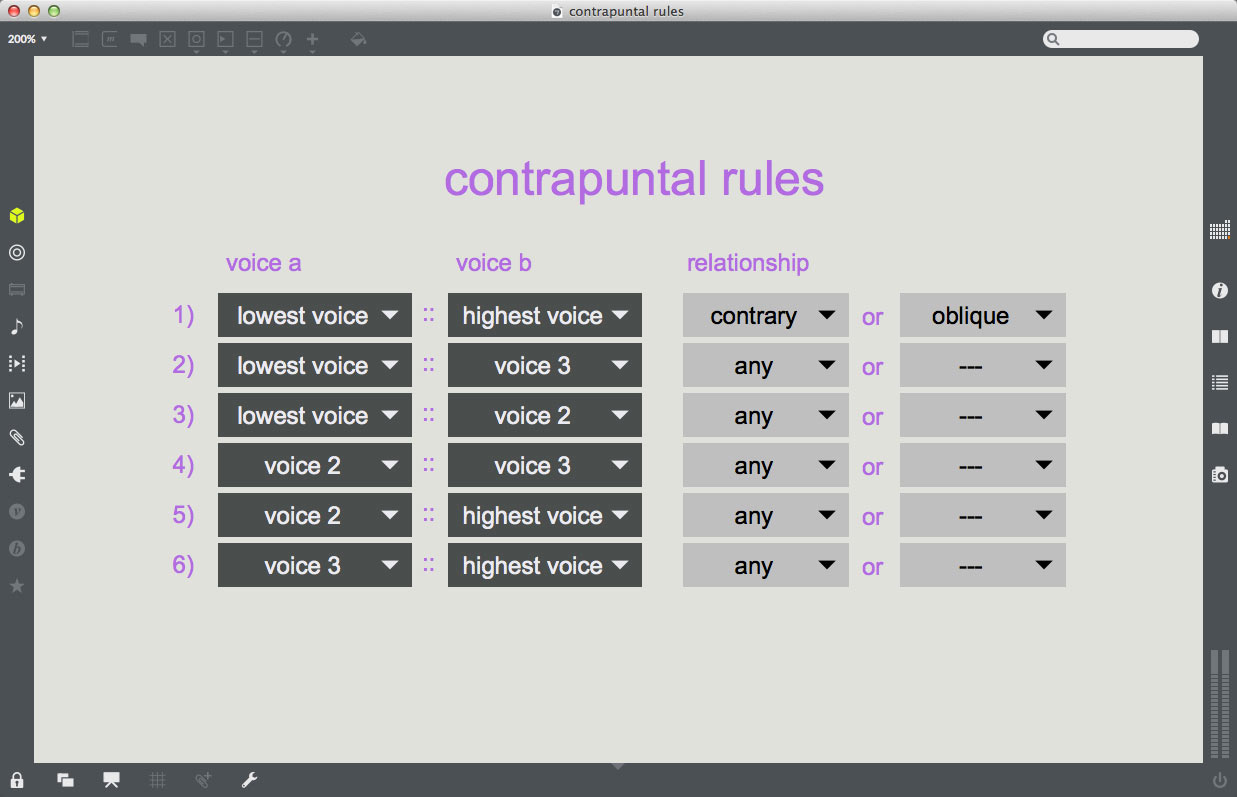
A final consideration might be the application of contrapuntal rules, such as the requirement that the lowest and highest voices move in either contrary or oblique motion. This could be implemented as yet another filter for candidate structures, allowing a contrapuntal rule to be specified for each two-voice combination.
example 5.2
Let’s create another musical example that implements these techniques to produce smoother movement between structures. We’ll broaden our harmonic palette this time to include four diatonic tetrachords—{0235}, {0135}, {0245}, and {0257}—and orchestrate our example for solo piano. We can use the same combinatoric approach as we did earlier, computing the inversional permutations of each tetrachord to develop our vocabulary. To keep the data set manageable, let’s limit generated material to a specific range of the piano, perhaps C2 to C6.
We’ll start by generating all of the permutations of {0235}, transposing each one so that its lowest pitch is C2, followed by each of the remaining three tetrachords. Before adding a structure to the database, we will add a range check to make sure that no generated structure contains any pitch above C6. If it does, it will be discarded; if not, it will be added to the database. We will repeat this process for each chromatic step from C#2 to A5 (A5 being the highest chromatic step that will produce in-range structures) to produce a total harmonic vocabulary of 2976 structures.
Let’s begin our realtime compositional process by selecting a random structure from among the 2976. In order to determine the next structure, we’ll begin by running all of the candidates through our semitonal movement algorithm, calculating the distances among voices in the first structure and all other structures in the database. To reduce disjunction between structures, but avoid repetitions and extremely small harmonic movements, let’s allow total movements of between 4 and 10 semitones. All structures that fall within that range will then be passed through to the interval check algorithm, where they will be tested against our intervallic preferences for each voice. Finally, all remaining candidates will be checked for violation of any contrapuntal rules that have been defined for each voice pair. Depending on how narrowly we set each of one these filters, we might reduce our candidate set from 2976 to somewhere between 5 and 50 harmonic structures. We can again employ an aleatoric variable to choose freely among these, given that each has met all of our horizontal criteria.
To give this algorithm a bit more musical interest, let’s also experiment with arpeggiation and slight variations in harmonic rhythm. We can define four arpeggio patterns and allow the algorithm to choose one randomly for each structure that is generated.
example 6:
While this example still falls into the category of initial experiment or étude, it might be elaborated to produce more compositionally satisfying results. Instead of a meandering harmonic progression, perhaps we could define formal relationships such as multi-measure repeats, melodic cells that recur in different voices, or the systematic use of transposition or inversion. Instead of a constant stream of arpeggios, the musical texture could be varied in realtime by the composer. Perhaps the highest note (or notes) of each arpeggio could be orchestrated to another monophonic instrument as a melody, or the lowest note (or notes) re-orchestrated to a bass instrument. These are just a few extemporaneous examples; the possibility of achieving more sophisticated results is simply a matter of identifying and solving increasingly abstract musical problems algorithmically.
Here’s a final refinement to our piano étude, with soprano voice reinterpreted as a melody and bass voice reinforced an octave below on the downbeat of each chord change.
example 6.1:
ORCHESTRATION
In all of the above examples, we limited our harmonic vocabulary to structures that we knew were playable by a given instrument or instrument group. Orchestration was thus a pre-compositional decision, fixed before the run time of the algorithm and invariable during performance. Let’s now turn to the treatment of orchestration as an independent variable, one that might also be subject to algorithmic processing and realtime manipulation.
This is an area of inquiry unlikely to arise in electronic composition, due to the theoretical lack of a fixed range in electronic and virtual instruments. In resigning ourselves to working with traditional acoustic instruments, the abstraction of “pure composition” must be reconciled with practical matters such as instrument ranges, questions of performability, and the creation of logical yet engaging individual parts for performers. This is a potentially vast area of study, one that cuts across disciplines such as mathematics/logic, acoustics, aesthetics, and performance practice. Thus, I must here reprise my caveat from earlier: the techniques I’ll present were developed to provide practical solutions to pressing compositional problems in my own work. While reasonable attempts were made to seek robust solutions, there are inevitably situations where theoretical purity must give way to expediency if one wishes to remain a composer rather than a full-time software developer.
The basic problem of orchestration might be stated as follows: how do we distribute n number of simultaneous notes (or events) to i number of instruments with fixed ranges?
Some immediate observations that follow:
a) The number of notes to be orchestrated can be greater than, less than, or equal to the number of instruments.
b) Instruments have varying degrees of polyphony, ranging from the ability to play only a single pitch to many pitches simultaneously. For polyphonic instruments, idiosyncratic physical properties of the instrument govern which kind of simultaneities can occur.
c) For a given group of notes and a fixed group of instruments, there may be multiple valid orchestrations. These can be sorted by applying various search criteria: playability/difficulty, adherence to the relationships among instrument ranges, or a composer’s individual orchestrational preferences.
d) Horizontal information can also be used to sort valid orchestrations. Which orchestration produces the least/most amount of melodic disjunction from the last event per instrument? From the last several events? Are there specific intervals that are to be preferred for a given instrument moving from one event to another?
e) For a given group of notes and a fixed group of instruments, there may be no valid orchestration.
Given the space allotted, I’d like to focus on the last three items, limiting ourselves to scenarios in which the number of notes to be orchestrated is the same as the number of instruments available and all instruments are acting monophonically.[3]
Let’s return to our earlier example of four-part harmonic events orchestrated for string quartet, with each instrument playing one note. By conservative estimate, a string quartet has a composite range of C2 to E7 (36 to 100 as MIDI pitch values). This does not mean, however, that any four pitches within that range will be playable by the instrument vector {Violin.1, Violin.2, Viola, Cello} in a one note/one instrument arrangement.
example 7

The most efficient way to determine whether a structure is playable by a given instrument vector—and, if so, which orchestrations are in-range—is to calculate the n! permutations of the structure and pass each one through a per-note range check corresponding to each of the instruments in the instrument vector. If each note of the permutation is in-range for its assigned instrument, then the permutation is playable. Here’s an example of a range check procedure for the MIDI structure {46 57 64 71} for the instrument vector {Violin.1 Violin.2 Viola Cello}.
example 8
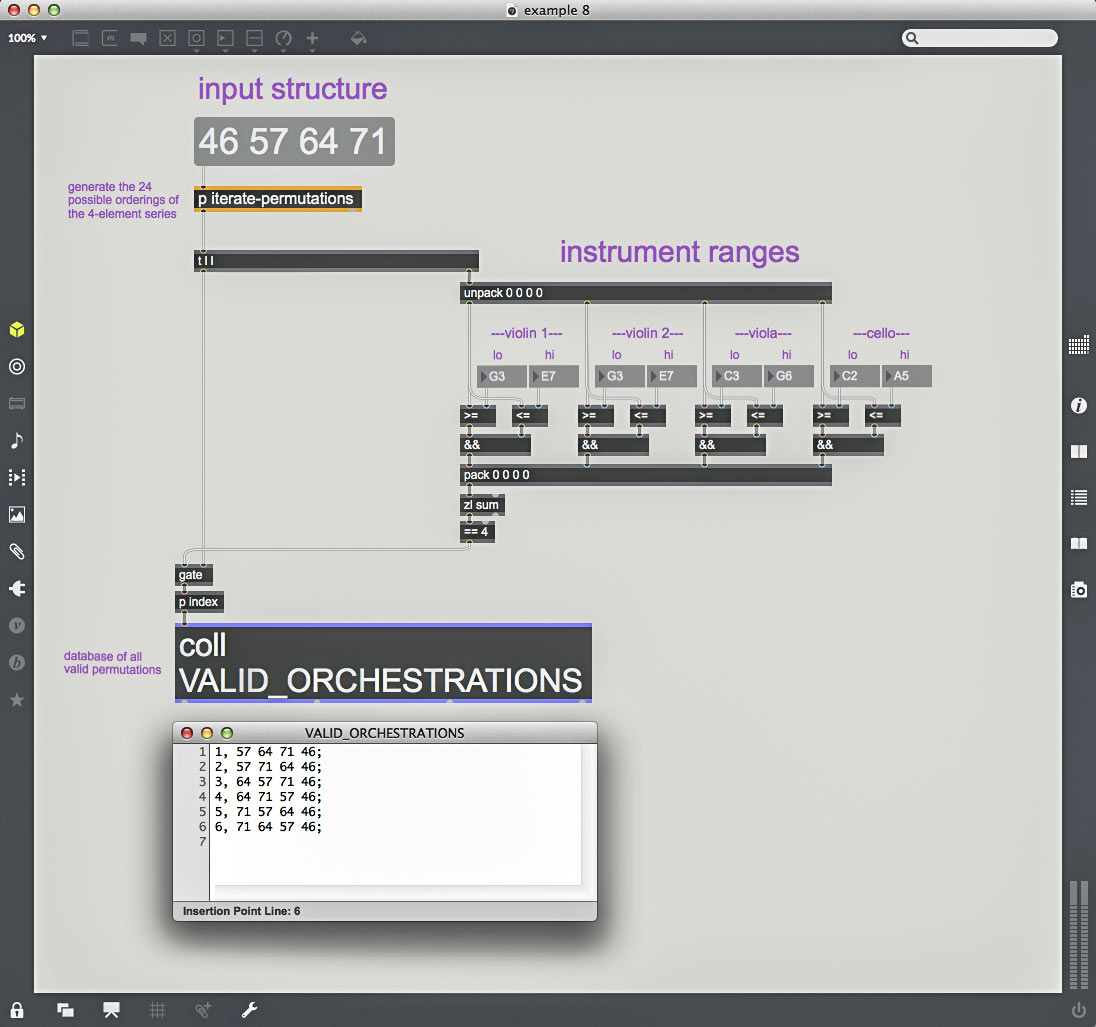
By generating the twenty-four permutations of the harmonic structure ({46 57 64 71}, {57 64 71 46}, {64 71 46 57}, etc.) and passing each through a range check for {Violin.1 Violin.2 Viola Cello}, we discover that there are only six permutations that are collectively in-range. There is a certain satisfaction in knowing that we now possess all of the possible orchestrations of this harmonic structure for this group of instruments (leaving aside options like double stops, harmonics, etc.).
Although the current example only produces six in-range permutations, larger harmonic structures or instrument groups could bring the number of playable permutations into the hundreds, or even thousands. Our task, therefore, becomes devising systems for searching the playable permutations in order to locate those that are most compositionally useful. This will allow us to automatically orchestrate incoming harmonic data according to various criteria in a realtime performance setting, rather than pre-auditioning and choosing among the playable permutations manually.
There are a number of algorithmic search techniques that I’ve found valuable in this regard. These can be divided into two broad categories: filters and sorts. A filter is a non-negotiable criterion; in our current example, perhaps a rule such as “Violin 1 or Violin 2 must play the highest note.” A sort, on the other hand, is a method of ranking results according to some criterion. Perhaps we want to rank possible orchestrations by their adherence to the natural low-to-high order of the instruments’ ranges; we might order the instruments by the average pitch in their range and then rank permutations according to their deviation from that order. For a less common orchestration, we might decide to choose the permutation that deviates as much as possible from the instruments’ natural order.
example 9
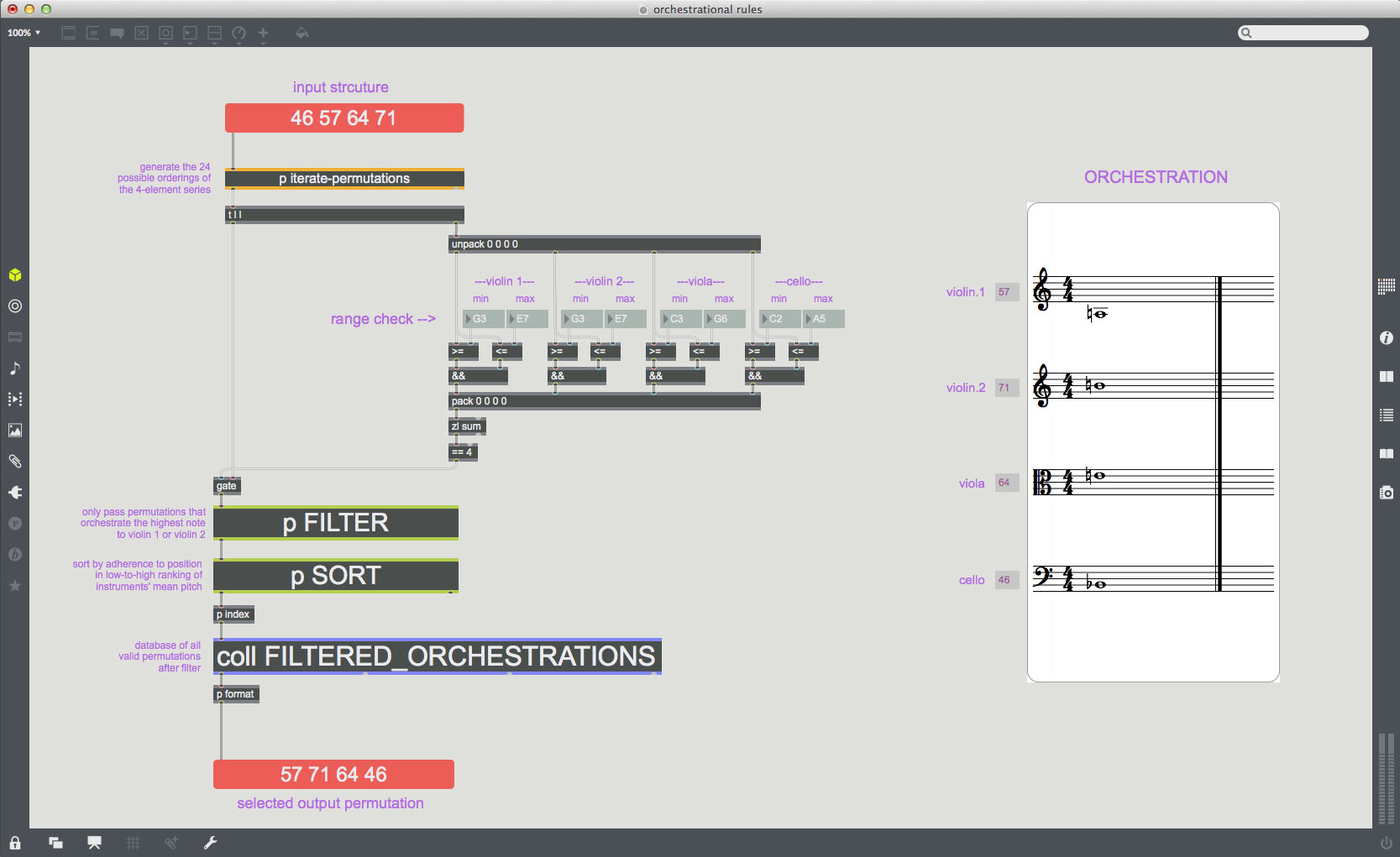
By applying this filter and sort, the permutation {57 71 64 46} is returned for the instrument vector {Violin.1 Violin.2 Viola Cello}. As we specified, the highest note is played by either Violin 1 or Violin 2 (Violin 2 in this case), while the overall distribution of pitches from low-to-high deviates significantly from the instruments ranges from low to high. Mission accomplished.
Let’s also expand our filtering and sorting mechanisms from vertical criteria to include horizontal criteria. Vertical criteria, like the examples we just looked at, can be applied with information about only one structure; horizontal criteria take into account movement between two or more harmonic structures. As we saw in our discussion of harmony, horizontal criteria can provide useful information such as melodic movement for each voice, contrapuntal relationships, total semitonal movement, and more; this kind of data is equally useful in assessing possible orchestrations. In addition to optimizing the intervallic movement of each voice to produce more playable parts, horizontal criteria can be used creatively to control parameters such as voice crossing or harmonic spatialization.
example 10

Such horizontal considerations can be combined with vertical rules to achieve sophisticated orchestrational control. Each horizontal and vertical criterion can be assigned a numerical weight denoting its importance when used as a sorting mechanism. We might assign a weight of 0.75 to the rule that Violin 1 or Violin 2 contains the highest pitch, a weight of 0.5 to the rule that voices do not cross between structures, and a weight of 0.25 to the rule that no voice should play a melodic interval of a tritone. This kind of a weighted search more closely models the multivariate process of organic compositional decision-making. Unlike the traditional process of orchestration, It has the advantage of being executable in realtime, thus allowing a variety of indeterminate data sources to be processed according to a composer’s wishes.
While such an algorithm is perfectly capable of running autonomously, it can also be performatively controlled by varying parameters such as search criteria, weighting, and sorting direction. Other basic performance controls can be devised to quickly re-voice note data to different parts of the ensemble. Mute and solo functions for each instrument or instrument group can be used to modify the algorithm’s behavior on the fly, paying homage to a ubiquitous technique used in electronic music performance. The range check algorithm we developed earlier could alternatively be used to transform a piece’s instrumentation from performance to performance, instantly turning a work for string quartet and voice into a brass quintet. The efficacy of any of these techniques will, of course, vary according to instrumentation and compositional aims, but there is undoubtedly a range of compositional possibilities waiting to be explored in the domain of algorithmic orchestration.
IDEAS FOR FURTHER EXPLORATION
The techniques outlined above barely scratch the surface of the harmonic and orchestrational applications of realtime algorithms—and we have yet to consider several major areas of musical architecture such as rhythm, dynamics, and form! Another domain that holds great promise is the incorporation of live performer feedback into the algorithmic process. Given my goal of writing a short-form post and not a textbook, however, I’ll have to be content to conclude with a few rapid-fire ideas as seeds for further exploration.
Dynamics:
Map MIDI values (0-127) to musical dynamics markings (say, ppp to fff) and use a MIDI controller with multiple faders/pots to control musical dynamics of individual instruments during performance. Alternatively, specify dynamics algorithmically/pre-compositionally and use the MIDI controller only to modify them, re-balancing the ensemble as needed.
Rhythm:
Apply the combinatoric approach used for harmony and orchestration to rhythm, generating all the possible permutations of note attacks and rests within a given temporal space. Use probabilistic techniques to control rhythmic density, beat stresses, changes of grid, and rhythmic variations. Assign different tempi and/or meters to individual members of an ensemble, with linked conductor cursors providing an absolute point of reference for long-range synchronization.
Form:
Create controls that allow musical “snapshots” to be stored, recalled, and intelligently modified during performance. As an indeterminate composition progresses, a composer can save and return to previous material later in the piece, perhaps transforming it using harmonic, melodic, or rhythmic operations. Or use an “adaptive” model, where a composer can comment on an indeterminate piece as it unfolds, using a “like”/”dislike” button to weight future outcomes towards compositionally desirable states.
Performer Feedback:
Allow one or more members of an ensemble to improvise within given constraints and use pitch tracking to create a realtime accompaniment. Allow members of an ensemble to contribute to an adaptive algorithm, where individual or collective preferences influence the way the composition unfolds.
Next week, we will wrap up the series with a roundtable conversation on algorithms in acoustic music with pianist/composer Dan Tepfer, composer Kenneth Kirschner, bassist/composer Florent Ghys, and Jeff Snyder, director of the Princeton Laptop Orchestra.
1. These having been theoretically derived and catalogued by 20th century music theorists such as Allen Forte. I should add here, however, that while theorists like Forte may have definitively designated all the harmonic species (pitch class sets of one to twelve notes in their prime form), the totality of individual permutations within those species still remains radically under-theorized. An area of further study that would be of interest of me is the definitive cataloguing of the n! inversional permutations of each pitch-class set of n notes. The compositional usefulness of such a project might begin to break down with structures where n > 8 (octachords already producing 40,320 discrete permutations), but would nonetheless remain useful from an algorithmic standpoint, where knowledge of not only a structure’s prime form but also its inversional permutation and chromatic transposition could be highly relevant.
2. In calculating the distance between voices, we are not concerned with the direction a voice moves, just how far it moves. So whether the pitch C moves up a major third to E (+3 semitones) or down a major third to Ab (-3 semitones) is of no difference to us in this instance; we can simply calculate its absolute value, yielding a value of 3.
3. Scenarios in which the number of available voices does not coincide with the number of pitches to be orchestrated necessitates the use of the mathematical operation of combination and a discussion of cardinality, which is beyond the scope of the present article.


















{kind=link}
{kind=link}
{kind=link}